IoT, M2M and the Need for Real-Time Analytics
Suppose you’ve developed a connected hardware product and are now in the market for a suitable software solution. Congratulations! With what feels like a new IoT platform every week, the choice is yours. Some providers are now trying to score with a special emphasis on real-time analytics. But do you really have the need for speed ? And if so, is real-time analytics in the cloud the appropriate solution for you?
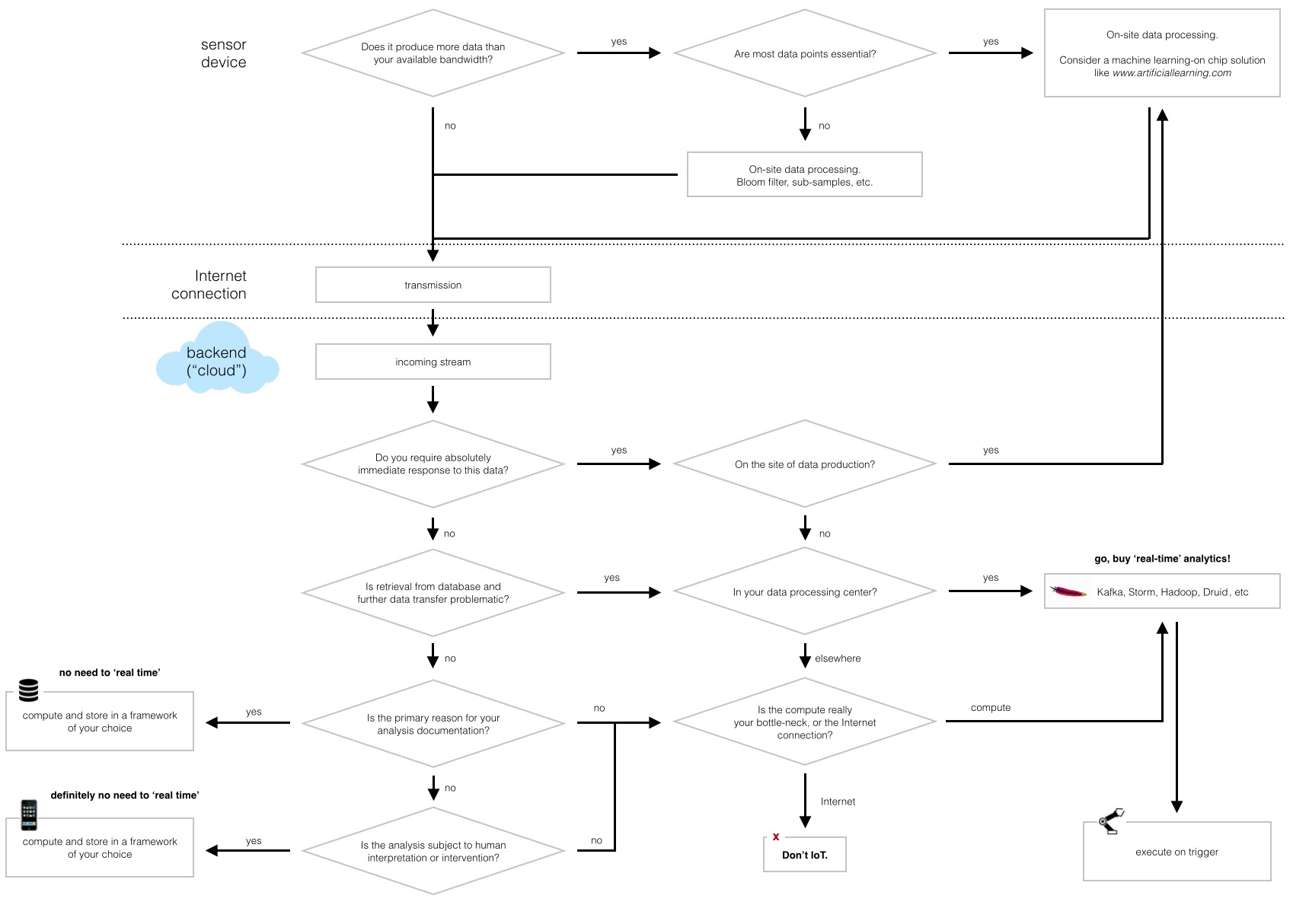 (open in separate tab to see that figure bigger…)
(open in separate tab to see that figure bigger…)
First, let me be clear that I absolutely see the point of specialised tools like Apache Kafka (message queuing), Storm (event processing), Spark or Hadoop (slicing/dicing). However, even if your platform provider offers such a real-time pipeline by default, you’re still facing a learning curve if you haven’t done ‘real time’ before, or in the worst case, considerable compute overhead that’s just not necessary (but that you nevertheless have to pay for!).
So let’s look at few IoT and M2M scenarios where real-time analytics are essential, and at some where you probably better off with an alternative solution. In the context of this article, I define M2M as applications where there’s defined input, processing and output, with little or no human intervention, whereas IoT is loosely devices in the consumer market such as connected thermostats and smoke detectors, wearable devices for ‘infotainment’ etc. Obviously this is only a very crude analysis of a few use cases. Your applications and milage may vary.
In general, my assumption is that there is little need for cloud-based stream processing in the IoT as I define it.
-
A simple case: A home automation device. If your device generates only little data that is aggregated into a simple visual representation for the end-user, analytics is not your problem. If we are looking at a floating point value per second, a day worth of data is about one tenth of the size of a MP3 music file on your phone - the easiest solution may be the transfer of the entire data to your user’s device and let an app do its thing. If you have a massive user base, your biggest problem may be I/O, but it’s unlikely that all users want to retrieve their data at the same time.
-
Now add the Internet-connected fridge (here, I said it!), the i-Crock-Pot and your smart heating system… Let’s imagine a very smart home in which many devices are controlled on the basis of continuous sensor measurements. And still, very likely, each of these devices is only going to produce a few bytes here and there. Why do real-time analytics in the cloud when you can get away with a few triggers either in those devices themselves or on whatever runs the gatekeeper/concierge app (cf. Interacting with a World of Connected Objects)?
In most IoT cases, you should be able to get away with outsourcing decisions to your users or their devices. In fact, your bottle neck is a human being.
M2M is where automated processes and big data collide. However, while predictive maintenance, asset tracking on massive scale and optimisation of business processes may indeed benefit from real-time analytics, there are use cases that can do entirely without and some where cloud-based computation may even be counterproductive.
-
A simple case: A pay-per-use device. ‘On’ for 3 hours… That would have to be a very expensive toy if you require real-time analytics. Very likely, your billing department is happy with a monthly summary of usage: A trigger in a conventional relational database might do the job.
-
Another simple case, but for a very different reason: The connected car. This Hitachi report talks about data rates of half a gigabyte per minute, if not more, that are generated by numerous sensors ranging from motor performance to street safety. Here, it is very advisable to perform most of the compute that doesn’t require integration of external information directly in the car. In most cases that may mean data reduction by sampling or filtering, other cases may require specialised hardware such as ‘machine learning’-on-board solutions before the most important features are transmitted over the network.
-
Complex industrial processes that require the integration of various data sources rely on the cloud as centralised data collection and compute centre. Long-term strategic decisions on the basis of periodic reports (that are interpreted by humans!) may not require real-time analytics, although streamed aggregation may take some pressure off your databases in the long run. However, if there is the opportunity to gain efficiency by split-second decisions, Storm, Spark (and their friends) are your best bet - if your internet connection can provide sufficiently fast feedback to any downstream components.
What if you need your response in milliseconds and your highly efficient compute is met by a stubborn TCP connection?
Well, maybe don’t IoT.